Project realised at the High Performance Humanoid Technologies Lab.
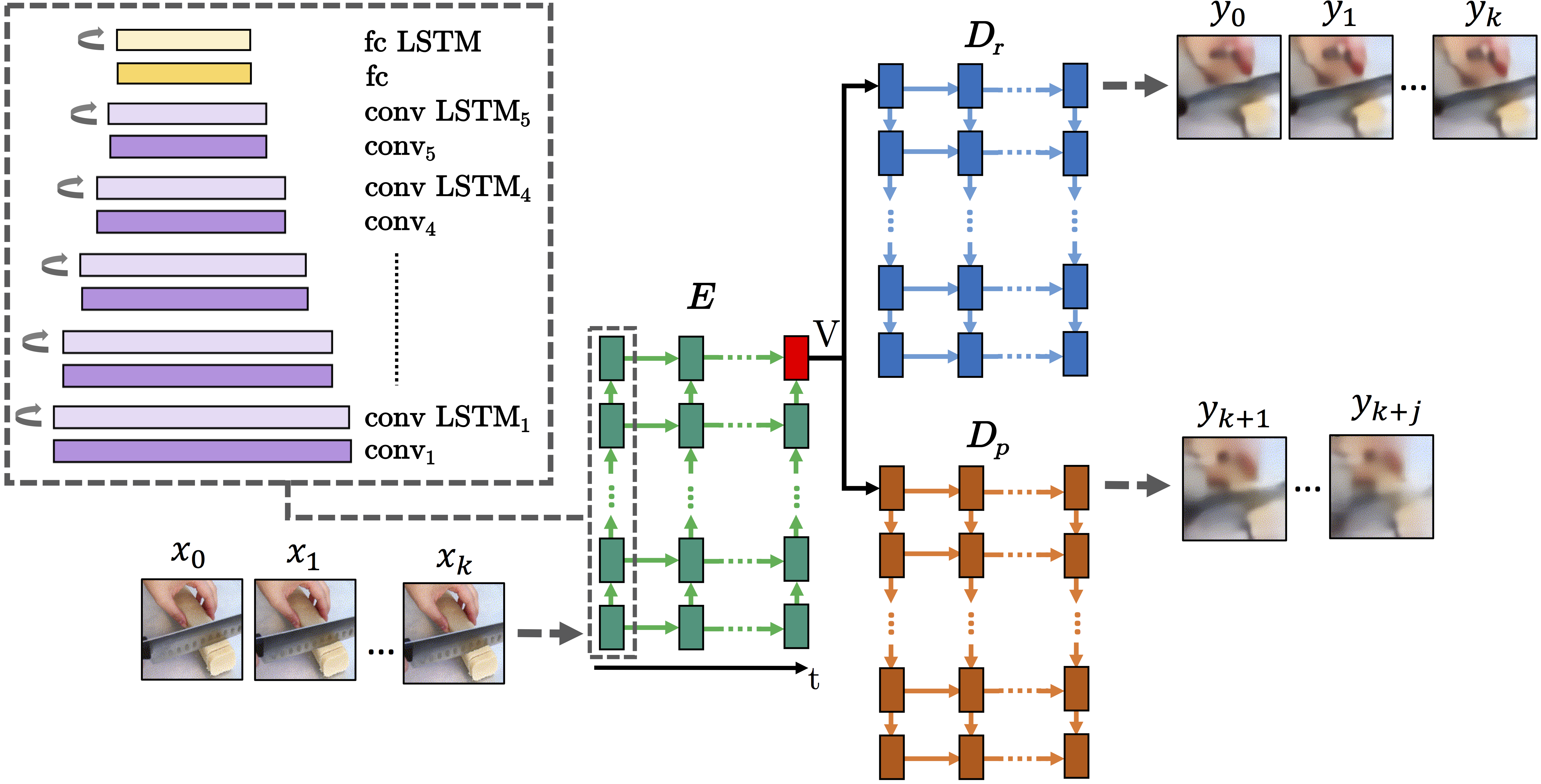
We present a novel deep neural network architecture for representing robot experiences in an episodic-like memory which facilitates encoding, recalling, and predicting action experiences. Our proposed unsupervised deep episodic memory model 1) encodes observed actions in a latent vector space and, based on this latent encoding, 2) infers most similar episodes previously experienced, 3) reconstructs original episodes, and 4) predicts future frames in an end-to-end fashion. Results show that conceptually similar actions are mapped into the same region of the latent vector space. Based on these results, we introduce an action matching and retrieval mechanism, benchmark its performance on two large-scale action datasets, 20BN-something-something and ActivityNet and evaluate its generalization capability in a real-world scenario on a humanoid robot.
Contribution: The contribution of this work is manifold: (1) We implement a new deep network to encode action frames into a low-dimensional latent vector space. (2) Such a vector representation is used to reconstruct the action frames in an auto-encoder manner. (3) We show that the same latent vectors can also be employed to predict future action frames. (4) We introduce a mechanism for matching and retrieving visual episodes and provide an evaluation of the proposed method on two different well-known action largescale datasets. (5) Finally, we demonstrate the possible application of our approach on the humanoid robot ARMAR-IIIa.
Authors: Jonas Rothfuss*, Fabio Ferreira*, Eren Erdal Aksoy, You Zhou and Tamim Asfour
(*equal contribution)
[arXiv]
Model Throughput Efficiency
In real-time applications such as robotics it might be important to know the processing speed of one’s model. Therefore, we conducted a small experiment in which we measured the throughput efficiency of our 20BN-trained model on one of our workstations (see specs below). We report two frame rates: one measured just with the encoder (since in our work we’re mainly interested in computing only the hidden representation at test time) and the other one measured over the entire model (encoder and both decoders):
Frames-per-second (encoder only): 273
Frames-per-second (encoder and both decoders): 102
tested on the following workstation set-up:
Hardware:
GPU: GeForce GTX TITAN X GM200-400
CPU: Intel(R) Core(TM) i7 4790K CPU @ 4.00 GHz (4 cores, 8 threads)
RAM: 32GB
Software:
Framework/API: TensorFlow 0.12.1 (32 queue runner threads), CUDA Version 8.0.61, CuDNN 5.1.10
OS: Ubuntu 14.04.5 LTS
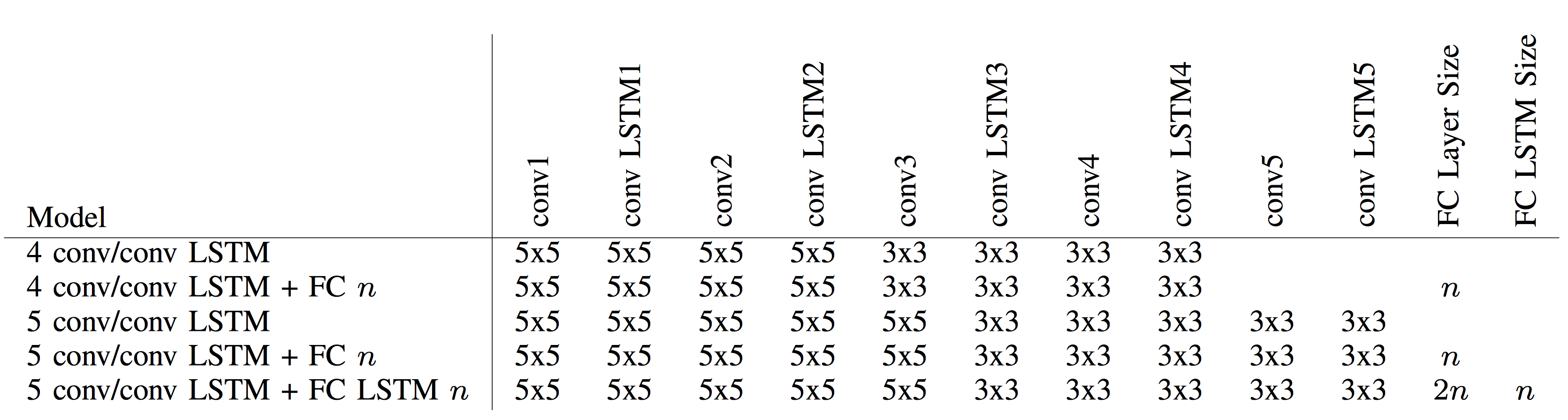
Trainings Overview
All trainings have been executed with our conv5/conv LSTM model with an FC LSTM layer of 1000 units, yielding 1000-dimensional latent representations. The ratio of images given to the encoder / decoder (prediction) / decoder (future) for our models is 5/5/5.

Model Configurations Overview
Models used during training – Layers from encoder input (left) to output (right). For conv and conv LSTM layers the filter size kxk is provided whereas fully connected (FC) layers and fully connected LSTM are characterized by their layer size n.